High Performance Spark를 읽고 간단히 정리해본 글입니다.
스키마의 기초
- 스키마의 정보와 그로 인해 가능해지는 최적화는 스파크 SQL과 코어 스파크 사이의 핵심 차이점 중 하나
- 스키마는 보통 스파크 SQL에 의해 자동으로 처리됨
- 데이터를 로딩할 때 스키마를 추측
- 부모 DataFrame과 적용된 트랜스포메이션에 의해 계산
printSchema()를 통해 보통 많이 DataFrame의 스키마를 확인- 복합적인 SQL type
스칼라 타입(scala type) SQL 타입 설명 예제 Array[T] ArrayType(elementType, containsNull) 한 가지 타입으로 이루어진 배열, null을 하나라도 갖고 있으면 containsNull이 true Array[Int] ⇒ ArrayType(IntegerType, true) Map[K,V] MapType(elementType. valueType, valueContainsNull) 키/값의 맵. 값에 null이 존재하면 valueContinsNull이 true Map[String, Int] ⇒ MapType(StringType, IntegerType, true) case class StructType (List[StructField]) 다양한 타입들로 이루어진 이름이 붙은 필드들 - 케이스 클래스나 자바 빈과 유사 case class Panda(name: String, age: Int) ⇒ StructType(List(StructField("name", StringType, true), StructField("age", IntegerType, true)))
DataFrame과 Dataset에서의 데이터 표현
- 텅스텐 데이터 타입은 스파크에 필요한 연산 형태에 따라 최적화된 특수한 메모리 데이터 구조 등의 장점
- 텅스텐의 데이터 표현 방식은 자바/kryo 직렬화보다 용량이 훨씬 적음
- RDD 33mb
- DataFrame 7mb
- 텅스텐은 자바 객체 기반이 아니기 때문에 온힙과 오프힙을 모두 지원
- Spark SQL에서는 kryo 직렬화와 칼럼 기반 저장 포맷만 사용해도 저장비용 최소화가 가능
'Spark' 카테고리의 다른 글
| [Spark] repartition vs coalesce 2 (0) | 2022.02.28 |
|---|---|
| Chapter 2. 스파크는 어떻게 동작하는가? (0) | 2022.01.31 |
| Chapter 1. 고성능 처리를 위한 스파크 시작하기 (0) | 2022.01.31 |
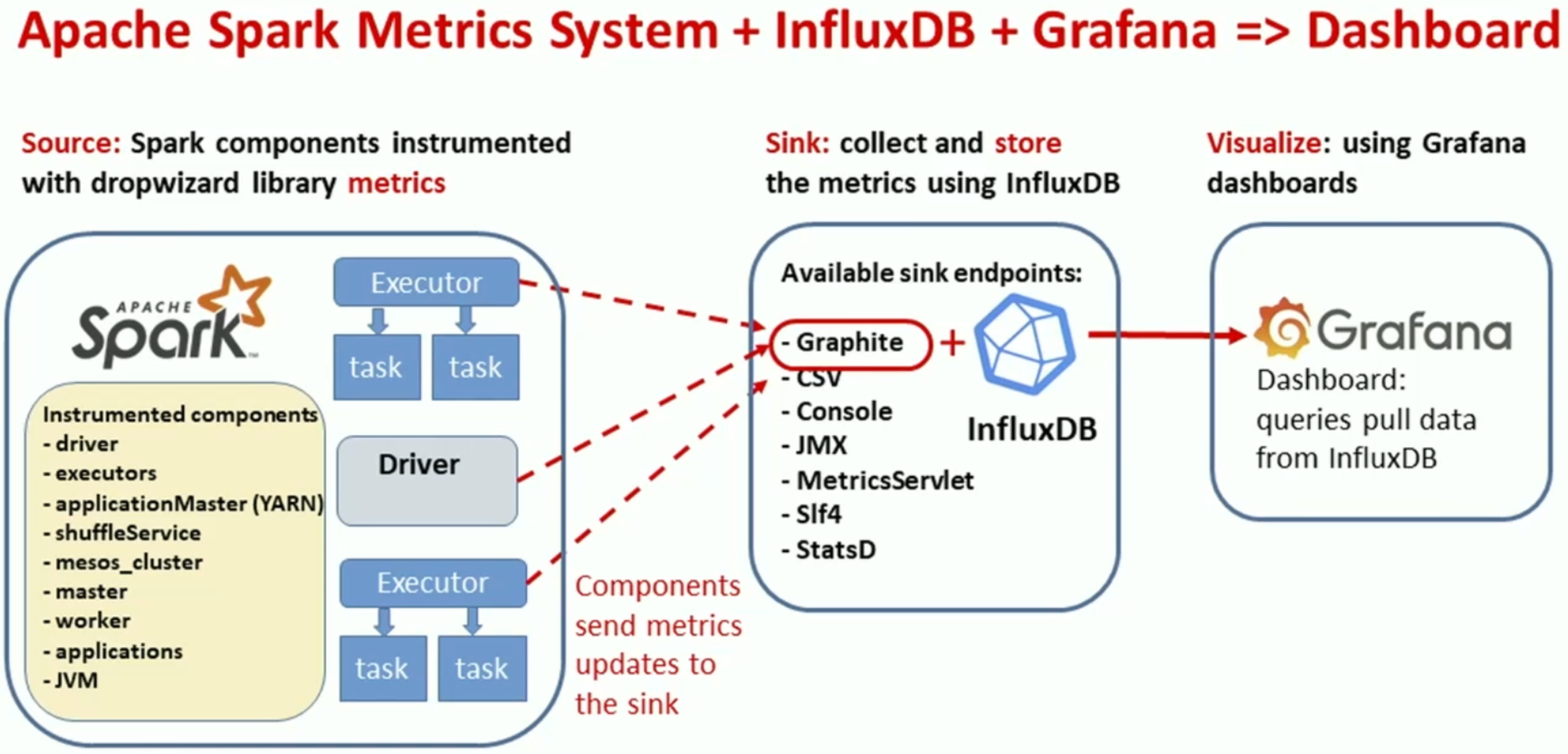
| [DATA+AI SUMMIT 2021] Monitor Apache Spark 3 on Kubernetes using Metrics and Plugins 요약 (0) | 2021.12.31 |
| [Spark] Spark 3.x Structured Streaming의 checkpoint는 k8s환경에서 어떻게 관리해야할까? (0) | 2021.12.31 |