repartition vs coalesce
repartition()은 파티션의 개수를 늘리거나 줄일 수 있지만 coalesce()는 줄이는 것 만 가능하다.
성능 차이
파티션의 개수를 줄이는 경우에는 coalesce()를 사용하는 것이 더 좋은데, 그 이유는 바로 셔플때문이다.
coalesce()는 셔플을 수행하지 않기 때문에 성능 측면에서 repartition()보다 더 좋다.
구현
coalesce()함수가 구현되어있고, repartition()에서 coalesce()를 호출하는 형태로 구성되어있다.
여기까지는 많이 알려진 내용인데, 개발하다보니 순서를 보장한 상태에서 하나의 파일로 파티션을 묶어야 할 때가 있었다.repartition()을 사용해서 묶었더니 정렬이 깨지거나 안되는 상황이 발생해서, 관련 테스트 결과를 기록한다.
orderBy().repartition(1).write- 이 경우에는 partition 내부의 block 단위로 정렬이 된다.
- 전체 파일이 정렬되지 않고 일부 정렬된 block들이 모여있는 상태처럼 보인다. (셔플이 수행되지 않은 것일까?)
- 가끔 정렬이 되어있는 경우도 있었다. 왜인지 아시는 분은 댓글로 알려주시면 정말 감사드립니다..
repartition(1).orderBy().write- 이게 어이없는 부분이었는데, 기존 100개의 partition을 읽고 해당 함수를 수행하니 100개의 partition으로 write했다.
- 각각의 partition은 잘 정렬되어있었다.
- 아마
1.에서의 block 단위가 100개의 partition으로 나뉘어진것이 아닌가 유추해본다.
orderBy().coalesce(1).write- 제일 추천하는 방법이다.
- 의도한대로 전체적으로 정렬이 되어있고, 1개의 partition으로 잘 묶여있다.
repartition(1)으로 묶었을 때와 비교해서 잘 정렬이 된 것으로 보아repartition(1)으로 묶을때는 셔플이 수행된 것 처럼 보인다.
coalesce(1).orderBy().write- 잘 동작한다. 직관적으로 1개로 묶고 정렬하는 방법이니 의도대로 잘 동작한다.
- 역시나
2.항목과 비교해보면repartition()방식이 아직도 잘 이해가 되지 않는다. 관련해서는 더 공부해봐야겠다.
coalesce() 동작 방식이 그림으로 잘 표현된 이미지가 있어서 첨부한다.
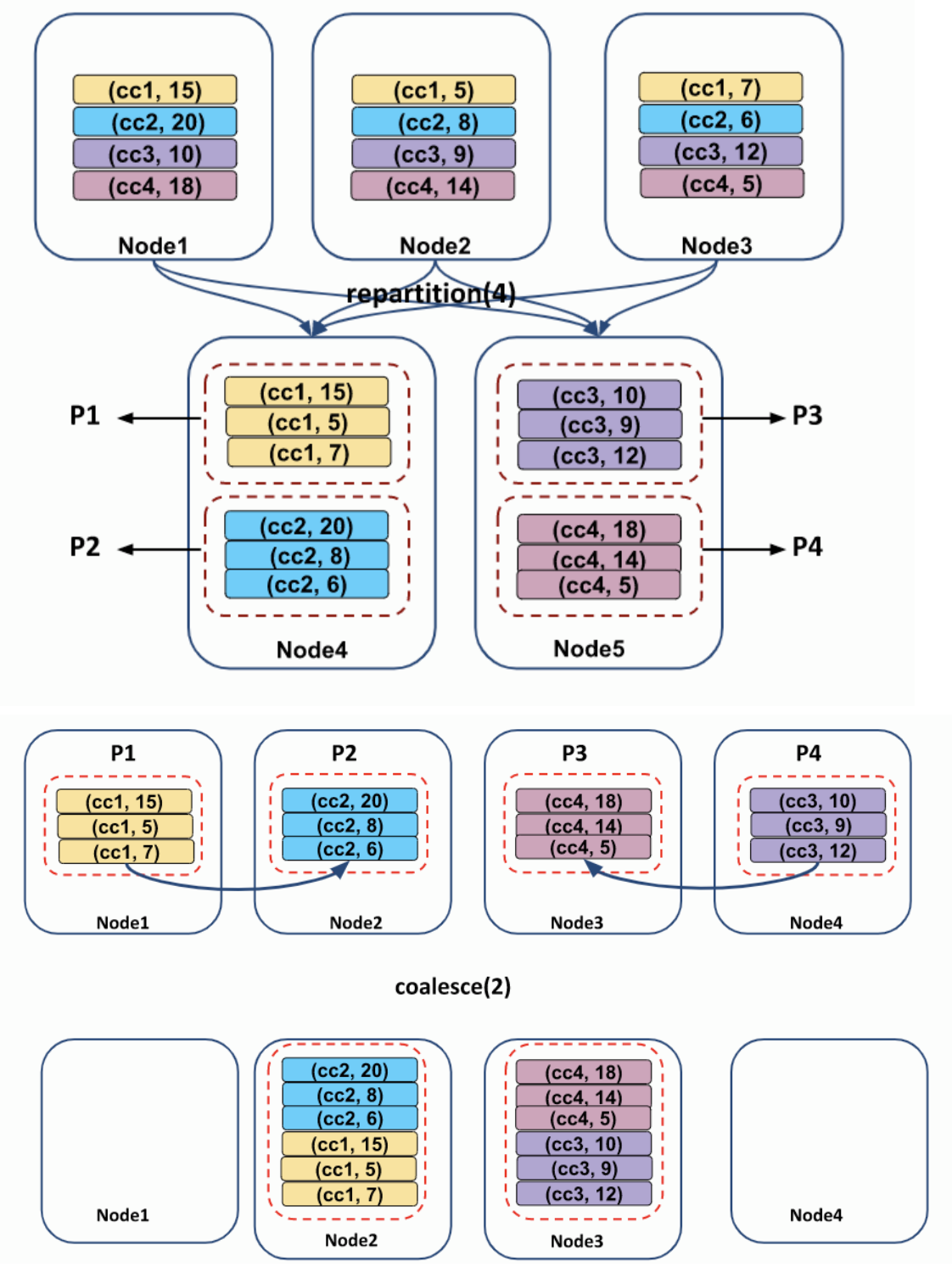
- 출처: https://pixipanda.com/tag/coalesce/
- 그런데 출처 페이지가 서비스 종료되었는지 현재 접근이 안된다
'Spark' 카테고리의 다른 글
| Chapter 2. 스파크는 어떻게 동작하는가? (0) | 2022.01.31 |
|---|---|
| Chapter 1. 고성능 처리를 위한 스파크 시작하기 (0) | 2022.01.31 |
| [DATA+AI SUMMIT 2021] Monitor Apache Spark 3 on Kubernetes using Metrics and Plugins 요약 (0) | 2021.12.31 |
| [Spark] Spark 3.x Structured Streaming의 checkpoint는 k8s환경에서 어떻게 관리해야할까? (0) | 2021.12.31 |
| [Spark-AI SUMMIT 2020] Fine Tuning And Enhancing Performance Of Apache Spark Jobs 요약 (0) | 2020.07.04 |